Cloud native is the perfect recipe for innovation, adaptability and engineering excellence – when it goes right. When it’s not right, it can be a monster spaghetti, a quality headache, and frustratingly inflexible. Why so negative?
Note: Here and there I’ve added my own observations in an italic paragraph or when notes takes up several paragraphs in between horizontal rules.
Consultant at IBM Garage
These are my scary stories
Summarising Twitter thread about the talk by Sara Dufour (@ComSaraDufour)
First problem: what is even Cloud Native?
One explanation of Cloud Native: SOA/ESB -> Micro-services -> Cloud Native
??? lots of small services, the platform is smart and the services are dumb ???
The emphasis on micro-services for Cloud Native does not feel right
Cloud Native Foundation: “micro-services, containers and dynamically orchestrated”
Still does not feel right to me
Interesting side effect of the Cloud Native Foundation is now that I’m commonly speaking to people who believe it can’t be cloud native without Kubernetes
– Sam Newman (@samnewman), Nov 19, 2020
If you ask 10 people what Cloud Native is, they will all know what Cloud Native is, but they will all come with a different definition.
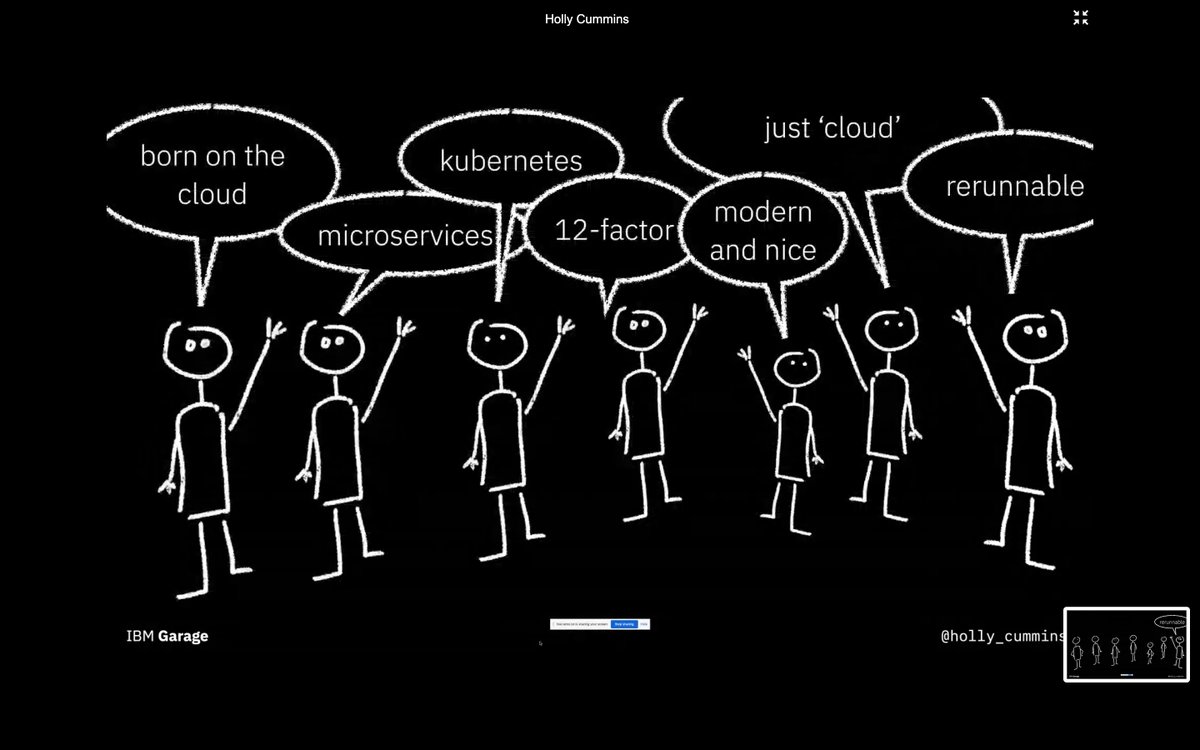
Some people will say:
- born on the cloud
- micro-services
- kubernetes
- devops
- it has been build in the past 5 years, it is modern and nice
- synonym for ‘cloud’
- idempotent: the problem with idempotent everyone says ‘What?’, you can rerun them
What is Cloud Native not? it is not a synonym for ‘micro-services’
So WHAT does “cloud native” actually mean? Everyone has their definition.
” If #cloud native has to be a synonym for anything, it should be ‘idempotent’*. “
#flowcon
* That’s latin for “having the same power”. (I knew this literary background would come in handy someday) – Sara Dufour (@ComSaraDufour), Nov 20, 2020
Cloud Native Foundation mentions immutable infrastructure! and micro-services exemplify this behaviour
why cloud native?
we want to build great products faster
@CloudNativeFdn’s definition keeps changing, so often that it’s now hosted on a Git: https://github.com/cncf/toc/blob/master/DEFINITION.md
Bottom line is: something that allows you to “make high-impact changes frequently & predictably with minimal toil, to build great products faster”. #ProductManagement
– Sara Dufour (@ComSaraDufour), Nov 20, 2020
Fail: the muddy goal?
what problem are we trying to solve?
Wishful mimicry
everyone else is doing it?
Assuming that if we have the same architectural patterns as companies like Netflix, we will have the same engineering success
-> it doesn’t really work like that.
we take the visual rituals but we do not take the culture
But very often, a #transformation is social-driven: “everyone’s doing it so we should too”. Many orgs know they want to be CN but don’t know what pb to solve.
– Sara Dufour (@ComSaraDufour), Nov 20, 2020
And just as anything else, a copy-paste from another organization won’t work —it’s just wishful mimicry. #frametheproblem #customize #flowcon
– Sara Dufour (@ComSaraDufour), Nov 20, 2020
Why cloud?
Why do we even want to go to the cloud?
cost reason: running in the cloud used to be cheaper
- economy of scale
- you don’t have to pay for most of your infrastructure most of the time
- elasticity based on demand: you don’t have to pay for things you don’t use; lots of servers when demand is peaking, rest of the year low amount of servers
- speed: partly faster hardware, but mostly time to market
- exotic capabilities: use expensive infrastructure
- GPU’s for machine learning are really expensive for your own datacenter
- quantum computing with quantum computers at .5 Kelvin (i.e. -272°C) difficult to have in your datacenter
Why cloud-native?
It turns out many people when they first moved to the cloud, they got electrocuted.
there are all sorts of bad things that can happen if you write software the way you wrote it (for on premise) in the cloud
=> 2011: 12-factors: how to write a cloud native application without being electrocuted
2010: the dawn of “cloud native” before 12-factors
2013: micro-services
Cloud Native in 2010 was about: here are the things to do to not get electrocuted when running in the cloud
where now Cloud Native is mostly limited to:
- runs in Kubernetes
- or lift-and-shift
It does seem perverse that Cloud Native, which I thought origins just implied ‘built to operate in cloud infrastructure’ as opposed to say, ‘lift-and-shift from a data centre’, now means ‘runs on Kubernetes.’. – Ian Cooper (@ICooper) Nov 20, 2020
So … there are so many definitions
Are we all going to agree on the goal?
=> lots of opportunity for confusion
Example: you go to the stakeholders with this cloud native solution
- and they were expecting micro-services
- or expecting faster time to market but we only got saving money
=> we get more opportunities for problems …
Fail: micro-services Envy
micro-services are not the goal, they are the means.
we’re going too slowly. we need to get rid of COBOL and make micro-services!
… but our release board only meets twice a year
– a bank
=> you will not actually go faster until you fix your release board
Containers are a good base. But number of containers !!??? It’s not a competition to see how many you can have
=> distributed monolith but without compile-time checking … or guaranteed function execution => there is a cost to distribution
reasons not to do micro-services
- small team
- not planning to release independently
- don’t want complexity of service mesh - or worse yet, rolling your own
-
domain model doesn’t split nicely
when we change one microservice, we need to change another one
=> cloud native spaghetti
=> distributed does not mean decoupled
each of our micro-services has duplicated the same object model … with twenty classes and seventy fields
why not a common library? we don’t want a common library because we don’t want coupling, which is fair
but the problem was: the domain model was common over all the micro-services => a shared library might have been a better approach in this case (though an anti pattern for micro-services)
The Mars explorer: instead of going around Mars it went into Mars
two controllers to control the navigation: base unit used imperial units vs the explorer used metric units
distributing did not help
=> need for Consumer-Driven Contract tests
pretty rare in our industry:
- hard to understand
- take work and coordination between teams
but gives you the confidence the micro-services will actually work together
when the confidence is not there that they will work together, you get …
Fail: the not-actually continuous CI and CD
CI/CD is not something you buy, it is a verb - not a tool - it is something you DO!
I’ll merge my branch in our CI next week …
CI/CD … CI/CD … CI/CD … we release every six months … CI/CD …
that is not continuous …
But …
It could be #ContinuousDelivery if your product demand is really 6 months. If it is, you have a constraint in sales/marketing more serious than technology
– Steve Smith (@SteveSmith_Tech), Nov 20, 2020
It could also be your perception of product demand is flawed, and one way to test that would be releasing features more frequently
– Steve Smith (@SteveSmith_Tech), Nov 20, 2020
How often should you integrate?
there is a spectrum
- actually continuous … but stupid
- every character
- every commit (several times an hour)
- every few commits (several times a day)
- once a day => trunk-based development
- once a week
- once a month
- once every six month
trunk-based development: you integrate at least once a day
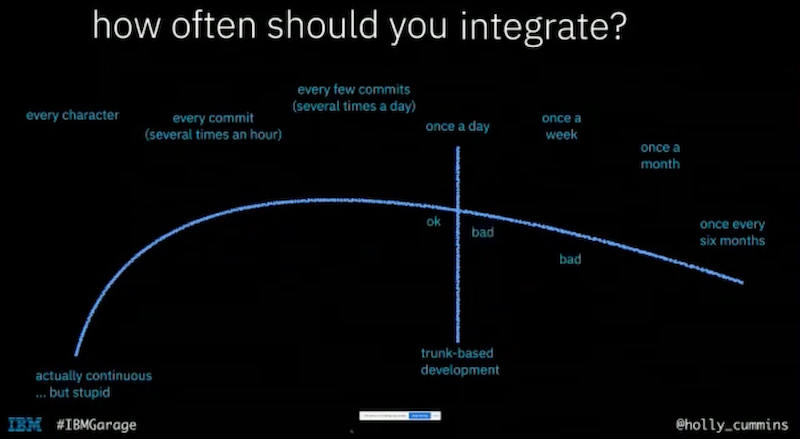
if you are at the left of that line, you can say you are in a state of trunk-based development if you are at the right of that line … it is not the best practice
my fit is: you integrate every few commits
How often should you release?
there is also a spectrum
- every push (many times a day) -> need a good handle on feature flags
- every user story
- every epic
- once a sprint
- once a quarter
- once every two years: old school
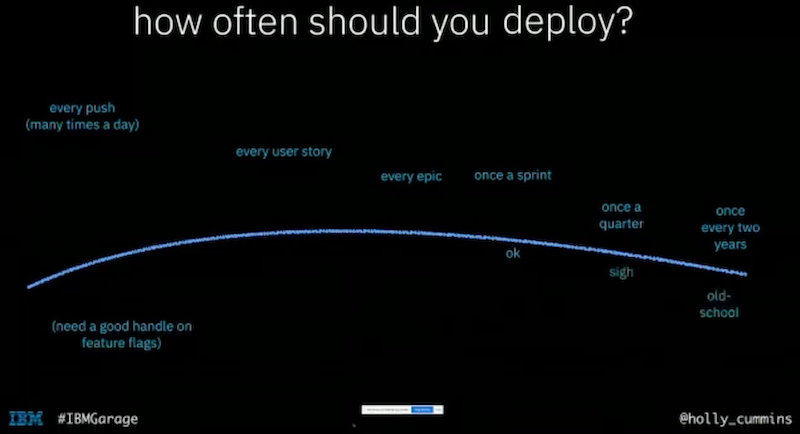
if you are going to deploy on every push, you will need a very good handle on feature flags
best practice: release once every sprint, anything less than that is old-school, anything more than that is great, every push is pretty hard core skills, every user story is slightly more attainable goal
then again …
- *release frequency depends on business demand, see Steve Smith
- increasing release frequency goes with a not to be taken light order of magnitude of investment in engineering skills
How often should you test in staging?
there is not really a spectrum on that -> continuously, on every push
We can’t release? But why? Why can’t you deploy more often?
often it comes down to that micro-services issue, the goal is independently deployable
but some organisations deploy them all at the same time:
we can’t release this microservice …
we deploy all our micro-services at the same time.
we can’t ship until every feature is complete
but …
if you’re not embarrassed by your first release it was too late
– Reid Hoffman
it is ok to get stuff out to get the feedback
The point of Cloud Native is … speed
What’s the point of an architecture that is expensive and that enable you to go faster if you don’t go faster?
=> you don’t get feedback
when driving a car, you never drive with your eyes closed however we often deliver software like that, we work for months without getting any feedback
but …
- Feedback is good engineering
- Feedback is good business: it helps the business take more accurate decisions
The “not-actually-continuous” CI/CD…
CI/CD is a verb —not a tool—, it’s something you DO!
Feedback is good #engineering and good #business. #cicd #tech #flowcon #ProductManagement
– Sara Dufour (@ComSaraDufour), Nov 20, 2020
If it is too scary to deploy? use deferred wiring, use feature toggles, use A/B tests, use canary deploys
often why these things don’t happen is because of …
Fail: lack of automation
our tests are not automated
=> we have to perform a long, manual QA because the tests are not automated
this actually means: we don’t know if our code works
and when you don’t know … systems will change and will behave in unexpected ways
your code may work, may be perfect, but a dependency might have changed and can change behaviour
we can’t ship until we have more confidence in the quality
that lack of confidence stops orgs from shipping
we don’t know when the build is broken
we should bring our build status everywhere on build radiuses to show when there is a problem and act on it when there is a problem
if you don’t have that, and the build breaks, and it stays broken and everybody thinks it is someone else’s problem
oh yes, that build has been broken for a few weeks …
why don’t we fix it, it stops giving useful information when it is always red
systems are going to behave in unexpected ways
with micro-services you need to have these automated contract tests
Fail: the locked-down totally rigid inflexible un-cloudy cloud
because Governance
a cloud that is so locked-down it lost its cloud characteristics
it takes us a week to start coding
two days to get a repo … two days to get a pipeline …
sometimes we don’t change the processes even when we go on the cloud
companies put so much Governance around cloud
this provisioner software is broken
with this provisioning tool you can spin VMs in seconds then they come back and tell us, it does not work, it takes 3 months to provision something
the provisioning tool does not work because … an 84-step pre-approval process is required before provisioning
they’ve taken this beautiful cloud and put so much governance around it … it is not going to work
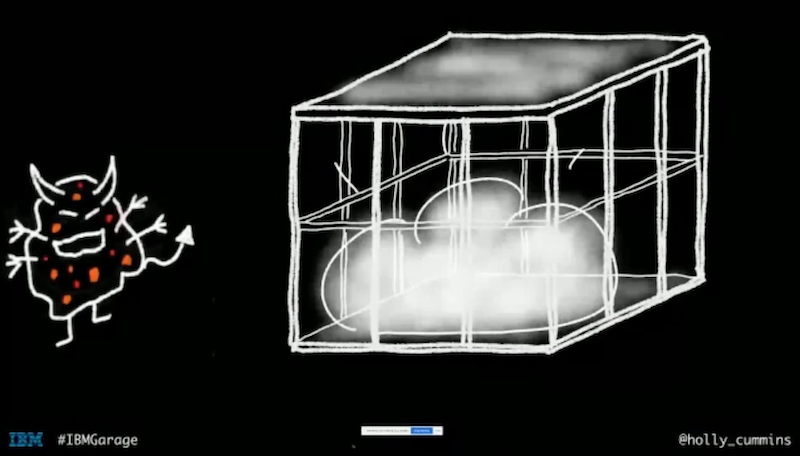
we’re going to change cloud provider to fix our procurement process
changing cloud provider because it took so long to provision because of the internal procurement process, the problem is not with your provider but with your internal structures
A locked-down totally rigid inflexible un-cloudy #cloud is not a good option.
If the #developers are the only ones changing, cloud native is not gonna work.
#culture #transformation #change #flowcon – Sara Dufour (@ComSaraDufour), Nov 20, 2020
We have this organisation with so much friction: there is a real cost. Developers will leave.
but governance is there for a reason because …
cloud can be expensive
Fail: the mystery money-pit
The cloud makes it so easy to provision hardware.
That doesn’t mean the hardware is free.
Often we provision something and they stop being useful, but we forgot about them -> it has a cost
Hey boss, I created a Kubernetes cluster … I forgot about it … 2 months later I realised it cost 1000 USD per month
2017 survey: 25% of 16.000 servers doing no useful work
-> financial impact as well as a climate impact
=> that is why there is governance
But …
There is surely nothing quite so useless as doing with great efficiency what should not be done at all.
– Peter Drucker
the cloud makes it very easy to provision something, but when it is not needed, it is very useless
we have no idea how much we’re spending on cloud
=> cloud to manage cloud costs
=> FinOps
Fail: micro-services ops mayhem
Ops in the cloud is harder
=> need for new disciplines like Site Reliability Engineering (SRE) (often overstated though)
make releases deeply boring so that we can do them often
But our use case is special …
there are some use cases that are genuinely special, for instance space
Russian space example: space probe with solar panel wings
we couldn’t get the automated checks to work, so we bypassed them
the machine code had an extra zero, the linter would have caught it, because it was broken, the engineer bypassed it and send it straight to the space probe, everything seemed to be working properly except the arms with solar panels that were supposed to follow the sun were not rotating, they only discovered that when the probe ran out of battery, once it was out of battery, anything they would send the probe would revive it
here there was no recoverability
- space: unrecoverable
- most other cases: pretty recoverable
recoverability spectrum:
- no recoverability
- lots of hand-offs: recoverability will be bad
- need for manual intervention: still bad
- back up fast with a bit of a data loss: a bit of a shame but pretty recoverable
- ideal: getting back in milliseconds with no data loss
=> hand-offs bad, automation is good => allows to release often
Ways to succeed at Cloud Native
-
have that clear goal of what you want to achieve
-
optimise for feedback
-
look at the whole system -> Systems Thinking.
If you automate something, change the processes around it that assume that the previously manual process is expensive and error prone.
=> Cloud Native is a good opportunity for Value Stream Mapping
=> look at the whole release process
=> avoid doing a whole bunch of optimisation in one area that are local optimisations, it will not give us the outcomes we want
The objective is: Optimise the system as a whole