Humans make mistakes, it’s a fact of life. Despite our best intentions, and no matter how many checks we put in place, sometimes things go wrong. It’s no different with software. To move at speed then it’s inevitable that production issues will happen. Sometimes it’s your code that doesn’t work as expected, sometimes dependencies break, sometimes infrastructure breaks. Sometimes that once in a lifetime event happens. Again.
This talk is a story about support. It’s a real life story of how what was a chaotic situation, with unhappy customers and developers, has been turned around to something that keeps our customers happy, and is even fun to be a part of.
single engineering team
Learning 1: you don’t need much when you start, short feedback loops are broken by too much process
two engineering teams
start to get chaotic
product teams have their favourite engineer to fix problems
-> introduce single slack channel for support
=> supporty: slack bot written in Typescript (by Bloom&Wild)
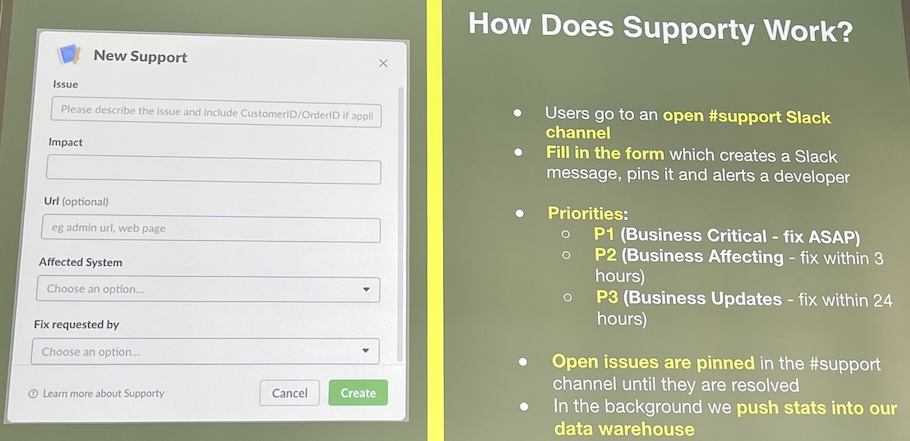
file support tickets via Slack form, engineers reply, everything is handled in single Slack threads
- gives a simple view of latest status
- clarity of ownership
- prioritisation
- data to learn from
Clear priorities build trust
- P1: Business Critical (SLA - 1 hour)
- customers unable to access the website
- production platform is inaccessible
- security issues
- P2: Business Affected (SLA - 3 hours)
- issues with admin that block business usage but don’t delay deliveries
- P3: Business Updates (SLA 24 hours)
- cosmetics
Learning 2: More Complexity = More Support, use tools at the right time to help bring order to the chaos
There is a trap when starting to use tools -> hide behind tools
we love it when you
- flag issues
- remember that there’s humons behind supporty
- give as much detail
- respond promptly
we’d rather you didn’t
- slack your favourite engineer ..
- …
The cost of an issue
P2 issue
- reports the app not working in the US
-
why? we had put in some additional security restrictions
- 143 replies in the thread
- 12 different people
- 5 hours to identify and resolve
review: 1 star going to 5 stars after fixing (time well spend?)
=> statistics and data are your friend
- Average open time vs Priority
- Number of Requests vs Number of code changes needed: when no code changes needed indicates that part of the app is extremely complicated
Time and Cost of Support
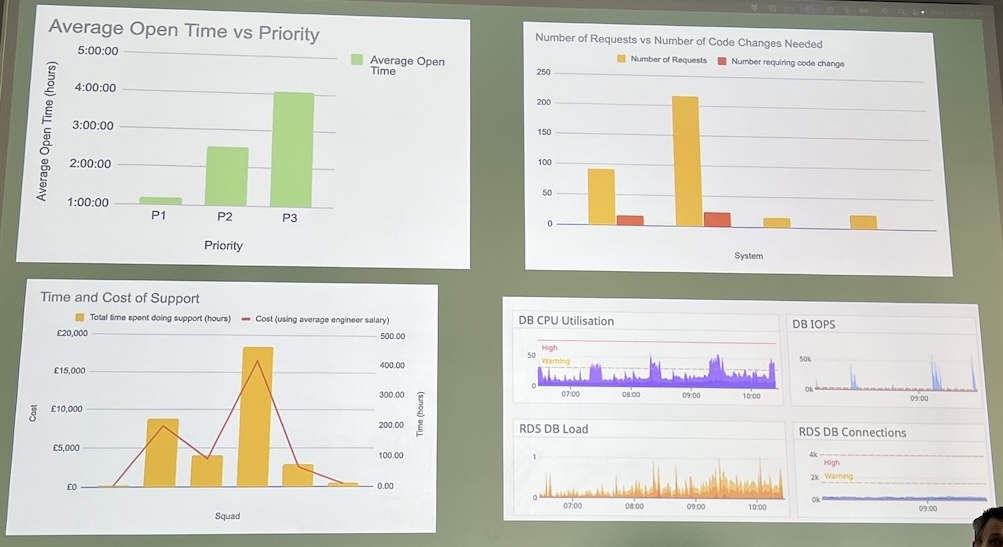
=> Make it visible
Change Failure Rate = number of production incidents / the number of production changes, how often do we make changes that break production
simplisticly: number of deployments vs number of major incidents
Minimise Time to Recover
- invest in good monitoring, alerting and observability
- have runbooks for key scenarios
- invest in fast deployment pipelines
- run game days to practice
- hold post mortems
Learning 3: Collect data so you can learn from it -> discover the cost of support
up until now everything was fine within business hours
after 6 pm what would happen? usually make its way to the CEO, then VP of Engineering receives a call, who tries to find someone
=> horrible situation for ones mental health
=> paid out of hours support
- it’s fair
- not knowing when your phone will ring is not fair
- thinking your phone might ring in the middle of the night is not fair
- it sets clear expectations
- it’s good for mental health
- it’s good for your company and your engineers
- it’s not expensive really
- compared to the cost of a production incident
Learning 4: Make it easier and fairer out of hours support
But support is not just about user requests is it?
- flaky tests
- slow queries
- …
=> gardening
even evil masters need a hobyy to escape the incompetence of their …
The Gardener
- monitoring and fixing production issues
- fixing staging
- merging and testing security fixes
- upgrades
- …
advantages
- enables engineers to understand areas outside of their domain
- helps shared ownership
- makes capacity planning clearer
makes a shared problem more clearly owned
Learning 5: supporting your system is not the same as supporting users, shared problems with single ownership
Scaling Challenges
- less knowledge of the whole domain since it’s bigger
- we find The Gardener isn’t working
- it’s weekly and therefore focusses on short term quick fixes
- doesn’t anchor responsibility
- when we really need capacity the gardner are often taken for high priority features
-> Each Squad has a Gardner
- tied together in a Community of Practice
- ownership and accountability
- craft and capabilty
- …
Making the investment visible -> Number of Stories: operational, tactical, strategic
Why didn’t we make a team of Gardeners?
- horrible team to be in
Learning 6: …
You Built it, Now Support It
- set clear expectations
- introduce process and tools at the right time
- collect data and learn
- pay for on call
- make ownership and autonomy your goal